ماهو اختبار A/B وماالفائدة منه وكيف يمكن تصميم اختبار A/B في موقع انترنت او نظام برمجي؟

آخر الاعضاء المنضمين


ماذا يعني الشفافية وقابلية التفسير في الذكاء الأصطناعي؟
ماذا يعني الشفافية وقابلية التفسير في الذكاء الأصطناعي؟ وكيف يمكن تحقيقها عندء بناء تطبيقات ذكاء اصطناعي؟
كيف يتم تقييم أداء نظام الترجمة الآلية بشكل آلي؟
يمكن القيام به باستخدام مقاييس ومعايير مختلفة. إليك بعض الطرق الشائعة لتقييم أداء نظام الترجمة الآلية بشكل آلي:
- BLEU (Bilingual Evaluation Understudy): BLEU هي إحدى القياسات الأكثر شيوعًا لتقييم أداء نظام الترجمة الآلية. يقوم BLEU بمقارنة الترجمة المولدة آليًا بالترجمة الإنسانية المرجعية ويقيم مدى تشابههما من خلال قياس الأتفاق بين الكلمات.
BLEU (Bilingual Evaluation Understudy) هو مقياس شائع يُستخدم لتقييم جودة الترجمة الآلية عن طريق مقارنتها بالترجمة الإنسانية المرجعية. يستخدم BLEU معلومات على مستوى الكلمات لقياس التشابه بين الترجمتين. يمكنك استخدام مكتبة Python لحساب مقياس BLEU بسهولة. فيما يلي شرح مفصل لمقياس BLEU مع مثال في Python:
أولاً، تحتاج إلى تثبيت مكتبة nltk (Natural Language Toolkit) إذا لم تكن مثبتة بالفعل. يمكنك فعل ذلك باستخدام الأمر التالي:
pip install nltk
استيراد المكتبات الضرورية:
import nltk from nltk.translate.bleu_score import sentence_bleu, SmoothingFunction
تحديد النصوص المرجعية والترجمة المستهدفة, النصوص المرجعية reference هيي النصوص التي تعبر عن الترجمة الصحيحة, اي دائما تحتاج إلى هذه النصوص لكي تقوم باختبار النظام, بالاضافة إلى النصوص المترجمة من قبل النظام الآلي candidate:
reference = [['the', 'quick', 'brown', 'fox', 'jumps', 'over', 'the', 'lazy', 'dog']] candidate = ['the', 'fast', 'brown', 'fox', 'jumps', 'over', 'the', 'lazy', 'dog']
بالنهاية يمكن حساب مقياس BLEU كمايلي:
bleu_score = sentence_bleu(reference, candidate)
NIST (The National Institute of Standards and Technology): يستخدم NIST مقاييس مشابهة لـ BLEU لتحسين تقييم أداء الترجمة الآلية من خلال مقارنة الترجمة بالترجمة الإنسانية المرجعية.
METEOR (Metric for Evaluation of Translation with Explicit ORdering): يقيم METEOR الأداء باستخدام عدة معايير مثل الأتفاق على مستوى الكلمات والترتيب والأمانة. يمكن أن يكون أكثر دقة في بعض الحالات من BLEU.
ROUGE (Recall-Oriented Understudy for Gisting Evaluation): يستخدم ROUGE بشكل رئيسي في تقييم جودة الخلاصات والملخصات النصية. يمكن أن يكون مفيدًا في تقييم الترجمة الآلية للملخصات النصية.
تقييم يدوي بشري: بالإضافة إلى القياسات الآلية، يمكن أيضًا اللجوء إلى تقييم بشري حيث يتم طلب آراء وتقييمات من الناس لفهم مدى جودة الترجمة. يمكن استخدام هذا التقييم لتحسين أداء نظام الترجمة.
يعتمد اختيار الطريقة على نوع النصوص والغرض من الترجمة. تذكر أنه يمكن تحسين أداء نظام الترجمة الآلية باستمرار من خلال تجربة وتعديل الموديلات والمعايير المستخدمة.
ماهي الشبكات العصبونية المتكررة؟
الشبكات العصبونية المتكررة Recurrent Neural Network هي نوع خاص من الشبكات العصبية الاصطناعية التي تتكيف مع بيانات السلاسل الزمنية أو البيانات التي تتضمن تسلسلات حيث يتم تغذية الاخراج من الخطوة السابقة كمدخل إلى الخطوة الحالية.
في الشبكات العصبية التقليدية تكون جميع المدخلات والمخرجات مستقلة عن بعضها البعض ولكن في حالات مثل عندما يكون مطلوباً التنبؤ بالكلمة التالية من الجملة تكون الكلمات السابقة مهمة وبالتالي هناك حاجة لتذكر الكلمات السابقة.
وهكذا ظهرت شبكات RNN والتي حلت هذه المشكلة بمساعدة الطبقات المخفية. تمتلك RNNs مفهوم الذاكرة الذي يساعد على تخزين حالات أو معلومات المدخلات السابقة لتوليد المخرجات التالية من التسلسل وهذا يجعلها قابلة للتطبيق على مهام مثل التعرف على خط اليد غير المقسم و المتصل أو التعرف على الكلام.
مشاكل نواجهها الـ RNNs:
- تلاشي التدرجات
- في تسلسل طويل، يتم ضرب التدرجات في (transpose أو منقول)مصفوفة الأوزان في كل خطوة زمنية. إذا كانت هناك قيم صغيرة في مصفوفة الوزن، فإن معيار (norm) التدرج يتقلص بمقدار أسي.
- انفجار التدرجات
- إذا كانت لدينا مصفوفة ذات أوزان كبيرة و اللاخطية في الطبقة التكرارية غير مشبعة، فسوف تنفجر التدرجات. سوف تتباعد الأوزان في كل خطوة. و قد نُضطر إلى استخدام معدل تعلم صغير حتى يعمل الانحدار التدريجي بشكل جيد.
أحد أسباب استخدام الـ RNNs هو ميزة تذكر المعلومات السابقة. ومع ذلك، قد تفشل RNN بسيطة في حفظ المعلومات لفترة طويلة دون بعض الحيل.
مثال لمشكلة التدرجات المتلاشية:
تمثل المدخلات رموزًا من برنامج بلغة C. سيحدد النظام ما إذا كان برنامجًا صحيحًا نحويًا أم لا. يجب أن يحتوي البرنامج الصحيح نحويًا على عدد صالح من الأقواس. و بالتالي، يجب أن تتذكر الشبكة عدد الأقواس والأقواس المفتوحة التي يجب التحقق منها، و ما إذا كنا قد أغلقناها جميعًها. يجب أيضا على الشبكة تخزين هذه المعلومات في حالات مخفية مثل العداد. ومع ذلك، و بسبب التدرجات المتلاشية، فإنها ستفشل في الحفاظ على هذه المعلومات في برنامج لمدة طويلة.
فريق من جامعة ستانفورد يطور نموذج لغوي قريب من أداء نموذج ChatGPT بكلفة اقل من 1000 دولار بهذه الطريقة
فريق من جامعة ستافورد قام بتطوير نموذج لغوي كبير LLM ينافس من حيث الأداء نموذج GPT3 تم بناءه بكلفة تقارب 1000$ وتم تسمية هذا النموذج ب Alpaca أو نموذج ألباكا.
يوضح الشكل التالي بنية نظام نموذج Alpaca والحقيقة فهي في غاية البساطة, وتعود بساطة النموذج إلى الاستفادة من النموذج المفتوح المصدر LLaMA الذي أطلقته فيسبوك بالاضافة إلى بناء البيانات التدريبية باستخدام نموذج text-davinci-003 الذي طورته شركة Open AI والذي يعتبر أساس نموذج ChatGPT

لتدريب نموذج لغوي على الشات او تنفيذ الأوامر، تحتاج إلى بيانات تدريبية تدعى instructions تحوي على عينات من الأسئلة والإجابة عنها، هذه العينات تساعد الشبكات العصبية على فهم الآلية التي يجب ان تستخلص فيها الإجابات من نصوص ضخمة.
الصورة بالمرفق توضح تفاصيل الأوامر التي تم توليد بيانات تدريبية من خلالها, حيث الدوائر الصغيرة في المنتصف تعبر عن الفعل الأساسي والدائرة الخارجية تعبر عن ماهو مطلوب بالضبط، مثلا:
- أنشأ: لائحة، شعر، جملة، قصة.
- أشرح: مفهوم، الأختلاف، المعنى، الهدف.
- صنّف: جملة، عنصر, حيوان, كلمة.

باستخدام هذه الأوامر، قام الفريق بتوليد 52 ألف أمر (بكلفة أقل من 500 دولار) عن طريق إرسال هذه الأسئلة إلى ChatGPT عن طريق Open AI API.
المثال التالي يوضح مثال كامل تم توليده:
{
"instruction": "Give three tips for staying healthy.",
"input": "",
"output": "1.Eat a balanced diet and make sure to include plenty of fruits and vegetables. \n2. Exercise regularly to keep your body active and strong. \n3. Get enough sleep and maintain a consistent sleep schedule."
},
{
"instruction": "What are the three primary colors?",
"input": "",
"output": "The three primary colors are red, blue, and yellow."
},
{
"instruction": "Describe the structure of an atom.",
"input": "",
"output": "An atom is made up of a nucleus, which contains protons and neutrons, surrounded by electrons that travel in orbits around the nucleus. The protons and neutrons have a positive charge, while the electrons have a negative charge, resulting in an overall neutral atom. The number of each particle determines the atomic number and the type of atom."
},
{
"instruction": "How can we reduce air pollution?",
"input": "",
"output": "There are a number of ways to reduce air pollution, such as shifting to renewable energy sources, encouraging the use of public transportation, prohibiting the burning of fossil fuels, implementing policies to reduce emissions from industrial sources, and implementing vehicle emissions standards. Additionally, individuals can do their part to reduce air pollution by reducing car use, avoiding burning materials such as wood, and changing to energy efficient appliances."
},
الجميل أنه تم نشر البيانات التدريبية للأوامر على الرابط التالي:
https://raw.githubusercontent.com/tatsu-lab/stanford_alpaca/main/alpaca_data.json
بعد أن أصبحت البيانات جاهزة, تم استخدام الأمر التالي لتدريب النموذج باستخدام مكتبة Transformers
torchrun --nproc_per_node=4 --master_port=<your_random_port> train.py \ --model_name_or_path <your_path_to_hf_converted_llama_ckpt_and_tokenizer> \ --data_path ./alpaca_data.json \ --bf16 True \ --output_dir <your_output_dir> \ --num_train_epochs 3 \ --per_device_train_batch_size 4 \ --per_device_eval_batch_size 4 \ --gradient_accumulation_steps 8 \ --evaluation_strategy "no" \ --save_strategy "steps" \ --save_steps 2000 \ --save_total_limit 1 \ --learning_rate 2e-5 \ --weight_decay 0. \ --warmup_ratio 0.03 \ --lr_scheduler_type "cosine" \ --logging_steps 1 \ --fsdp "full_shard auto_wrap" \ --fsdp_transformer_layer_cls_to_wrap 'LLaMADecoderLayer' \ --tf32 True
بعد ذلك تم تدريب نموذج LLaMA ب 7 مليار بارامتر باستخدم 4 معالجات رسومية NVIDIA A100 80GB غيغابايت, من الجدير بالذكر أن معالج واحد من هذا النوع قد يصل سعره إلى 20 الف دولار ولكن باستخدام الحوسبة السحابية ذكر المؤلفين أن التدريب استغرق 3 ساعات بكلفة 100 دولار.
هذه بعض الأمثلة عن إجابة النموذج المطوّر على بعض الأسئلة:

تفاصيل المشروع متاحة على الرابط:
https://github.com/tatsu-lab/stanford_alpaca
تحسن طفيف لنسخة ChatGPT4 في حل مسائل في البرمجة التنافسية
أعلنت شركة OpenAI عن نسخة جديدة من ChatGPT وصرَحت بانها تتفوق على النسخة الثالثة ChatGPT3.5 بقدرتها على فهم فهم مسائل أكثر تعقيدا.
مالفت نظري ان ChatGPT بدء تقييمه على حل مسائل مسابقات برمجية Competitive Programming من خلال منصة CodeForces واستطاعت النسخة الرابعة الوصول إلى تحسن بسيط جيد مقابل النسخة السابقة.
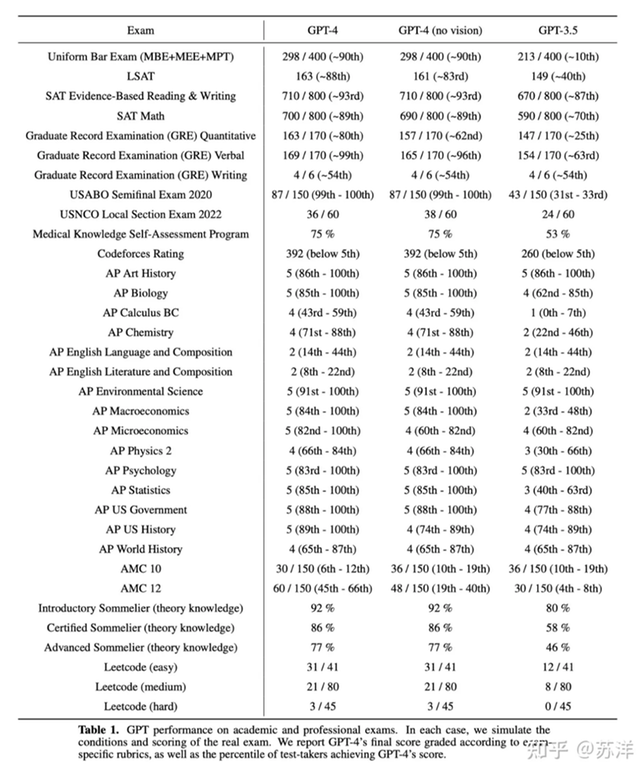
استطاعت النسخة الثالثة الوصول إلى تقييم 260 فقط، أما النسخة الرابعة فتمكنت من الوصول إلى تقييم قدره 392 بتحسن ضئيل. رغم ذلك لا يتجاوز هذا التقييم الجديد ال 5% على المنصة.
بينما استطاع ChatGPT4 الوصول إلى تقييم تقريبا 90% في SAT Math الذي يختبر قدرات الطلاب قبل المرحلة الجامعية في الرياضيات, بالاضافة إلى درجة 90% في امتحان البار الذي يجب ان يجتازه كل محام ممارس في الولايات المتحدة الأميريكة لم يستطع ChatGPT4 تحقيق أكثر من 5% في البرمجة التنافسية.
لا أقول أن 5% هي درجة سيئة لنموذج ذكاء صنعي, ولكن هذه الدرجات المتدنية في البرمجة التنافسية والدرجات العالية في الامتحانات المعيارية تظهر أن الذكاء الصنعي قادر ان يتعلم بسهولة عند تقديم بيانات له بشكل واضح وعندما تكون الإجابات للأسئلة التي نسأل عنها سهلة الاستدلال من النص. أما عند الانتقال إلى اختبار مقعد يحتاج إلى تحليل عميق للنص وتقديم حل غير موجود على الأغلب في البيانات التدريبية يصبح أداء الذكاء الصنعي أسوأ بكثير.

