تحسن طفيف لنسخة ChatGPT4 في حل مسائل في البرمجة التنافسية
أعلنت شركة OpenAI عن نسخة جديدة من ChatGPT وصرَحت بانها تتفوق على النسخة الثالثة ChatGPT3.5 بقدرتها على فهم فهم مسائل أكثر تعقيدا.
مالفت نظري ان ChatGPT بدء تقييمه على حل مسائل مسابقات برمجية Competitive Programming من خلال منصة CodeForces واستطاعت النسخة الرابعة الوصول إلى تحسن بسيط جيد مقابل النسخة السابقة.
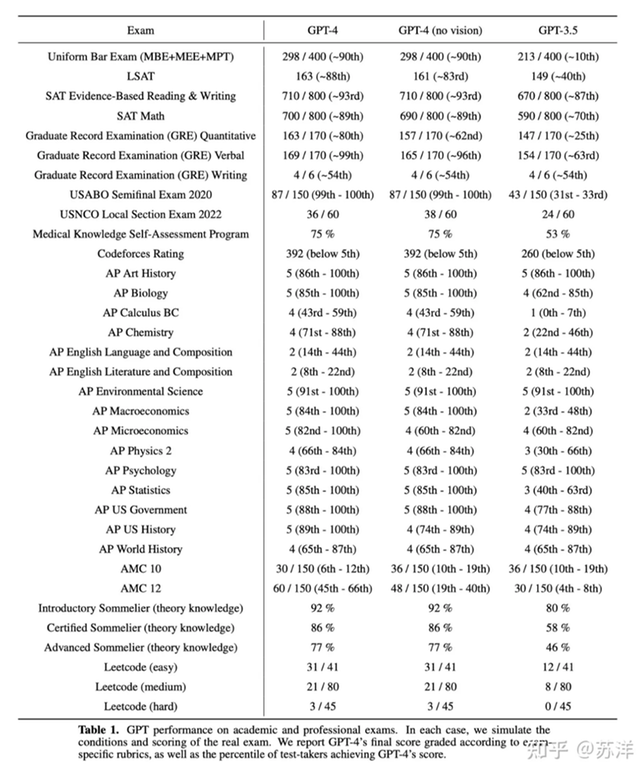
استطاعت النسخة الثالثة الوصول إلى تقييم 260 فقط، أما النسخة الرابعة فتمكنت من الوصول إلى تقييم قدره 392 بتحسن ضئيل. رغم ذلك لا يتجاوز هذا التقييم الجديد ال 5% على المنصة.
بينما استطاع ChatGPT4 الوصول إلى تقييم تقريبا 90% في SAT Math الذي يختبر قدرات الطلاب قبل المرحلة الجامعية في الرياضيات, بالاضافة إلى درجة 90% في امتحان البار الذي يجب ان يجتازه كل محام ممارس في الولايات المتحدة الأميريكة لم يستطع ChatGPT4 تحقيق أكثر من 5% في البرمجة التنافسية.
لا أقول أن 5% هي درجة سيئة لنموذج ذكاء صنعي, ولكن هذه الدرجات المتدنية في البرمجة التنافسية والدرجات العالية في الامتحانات المعيارية تظهر أن الذكاء الصنعي قادر ان يتعلم بسهولة عند تقديم بيانات له بشكل واضح وعندما تكون الإجابات للأسئلة التي نسأل عنها سهلة الاستدلال من النص. أما عند الانتقال إلى اختبار مقعد يحتاج إلى تحليل عميق للنص وتقديم حل غير موجود على الأغلب في البيانات التدريبية يصبح أداء الذكاء الصنعي أسوأ بكثير.